Steep Part 2: Imitation Learning to Complete Rocket Suit Races
After spending considerable effort developing a data collection and processing pipeline, I wanted to use the tools I created to look at a slightly different problem. With the ski race course results, we were able to achieve competitive times (although not consistently). We now direct our tools to a separate race mode in Steep using a rocket suit rather than skis. The rocket suit races require more controls to navigate the course and are much less forgiving—unlike in the ski courses, a single crash terminates the attempt. However, the rocket suit races allow a set of guidelines that can be toggled. Are these guidelines sufficient to navigate a course using imitation learning?
Rocket Suit Introduction
Recall that one of the hypotheses for the poor performance on the ski courses was that there were insufficient landmarks to allow navigation in the absense of temporal knowledge. I hope to explore this hypothesis by using a rocket suit course, which permits displaying guidelines which, if properly followed, will lead to a successful completion of the course. Without considering these guidelines, this should be a much more challenging problem. First, the course is more complex, so that more key presses are required to navigate the course. This type of race is also less forgiving, since a single crash ends the attempt. Also, there is another dimension that we need to pay attention to, since the altitude above the ground is very important. And finally, the importance of a coherent trajectory is amplified. Many of the maneuvers cannot be executed unless the avatar is in the proper position initially. For instance, I quickly identified several instances while attempting the course myself in which no combination of navigation commands would lead to a successful completion if I took the wrong trajectory to arrive at that specific location.
From my experience in attempting to create a neural network capable of navigating the ski courses, I have learned to temper my expectations. As such, I am only going to try to successfully navigate a single course using the rocket suit. The course of interest can be seen in the video below, which has the guidelines toggled on.
We can clearly identify the many additional challenges associated with the wing suit race course that the network will need to overcome. However, the wing suit course has one very large advantage over our previous ski courses—we can turn on “guidelines” that trace out an efficient trajectory through all of the checkpoints to the finish line, as shown in the sample frame below. So while there are several reasons to expect our network to perform poorly in this more complicated environment, there is the trade-off that we now have landmark features to help the network identify the proper choice of navigation.
To achieve a competitive time in this course, we need to introduce a new key that was not present in the ski course. The wing suit is not simply a glider but is a rocket suit that has a propellant that can be toggled. The use of the propellant is very obvious in the ideal video where I complete the course. However, nothing in our past results suggest that we should anticipate so much success to consider the optimal time upon a succesful completion of the course. For this reason, we remove this functionality and remap the training data to always have a label that does not consider using the propellant. Of course, we can always go back to the original recorded data if we feel we are prepared to tackle the full problem of the wing suit.
Data Collection
I collected data in the same way as before, recording just under 450,000 labeled frames from the same course. Using our data augmentation techniques, I expanded our dataset to 720,000 labeled frames. Our data augmentation methods were especially useful now that we have six relevant key combinations so that we are not limited by our least-frequent key. Using our labeled frames, I again trained a version of ResNet50 to learn the appropriate navigation choice for a given frame.
Network Evaluation
The trained ResNet50 showed very good training accuracy but poor validation accuracy, only performing slightly better than random on frames it had not been trained on. The validation loss and accuracy shown in the figure below are very poor. The validation loss fails to decrease with additional epochs, and the validation accuracy fails to increase with additional epochs. These plots suggest that we are again dealing with overfitting problems.
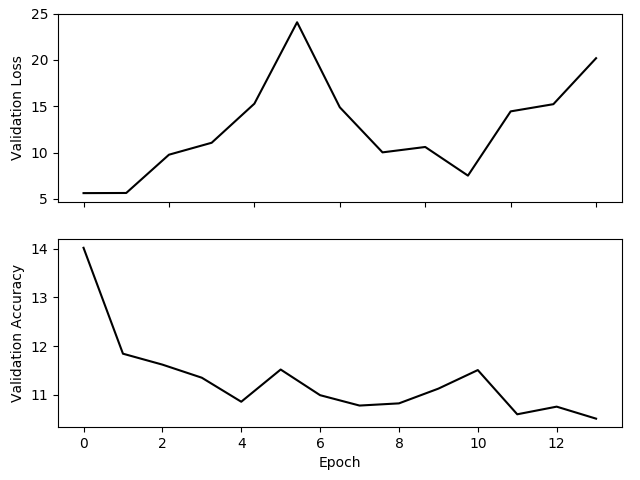 Both the validation loss and validation accuracy fail to improve with additional epochs.
Both the validation loss and validation accuracy fail to improve with additional epochs.
Although the performance of the network is very poor in terms of metrics calculated using a validation set, the performance in practice is not neccessarily the same. The reason for this is that the ground truth labels are a bit fuzzy. For many of the frames, there are multiple acceptable navigation commands that would allow successful completion of the course. There are also some frames where only a single navigation command would prevent termination of the course, either from a crash or a significant deviation from the optimal trajectory. In evaluating the network on the trained course, it is not overly successful, since it never reaches the second checkpoint. However, the network seems to behave more like an untrained human than a glitchy bot. In the video below, we clearly see that the network has identified the importance of the guidelines and does a reasonable job of trying to follow them. Unfortunately, quantifying the netowrk evalution the wing suit course is more challenging since the attempt fails after a single crash.
Reducing Overfitting Through Regularization
Despite the obvious shortcomings with the performance of the trained network, it does seem to illustrate some ability to understand the navigational goals and follow a reasonable trajectory. This glimpse of potential is enough for me to try some network architecture modifications to try to reduce overfitting. The two main methods at our disposal are dropout, in which certain nodes in the fully-connected layers are ignored during training, and weight decay, which penalizes large values for the network weights. (For technical reasons, $\ell_2$ regularization is not optimal for adaptive gradient optimizers such as Adam. For more information, see here).
I tried four different combinations of dropout and weight decay to try to identify a regularized network less susceptible to overfitting our training data:
- 50% dropout on fully-connected layers
- Weight decay of
$10^{-4}$ - 50% dropout on fully connected layers + weight decay of
$10^{-4}$ - 50% dropout on fully connected layers + weight decay of
$10^{-3}$
For each of these modified architectures, the network was trained for 10 epochs on the 720,000 labelled frames dataset. In all instances, the network showed very good metrics on the training dataset but again showed poor performance on the validation set metrics. The validation loss and accuracy are again shown below. Both of these quantities fail to improve with additional epochs for any of the suggested changes.
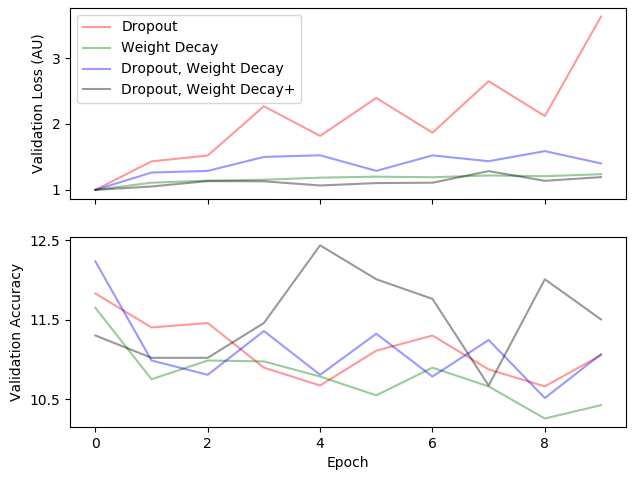 Both the validation loss and validation accuracy fail to improve with additional epochs even with the regularization attempts.
Both the validation loss and validation accuracy fail to improve with additional epochs even with the regularization attempts.
Evaluating the Regularized Networks
Failure to improve upon the loss or accuracy on the validation set is disappointing, but again, the real test comes from evaluating the network in practice. As a quick spoiler, none of the networks achieve amazing performance in navigating the course successfully. This should come as no surprise given the validation set metrics. However, despite this, there are a number of interesting conditions in which we can evaluate the trained networks. All of the below videos were generated using the network with dropout and less severe weight decay trained after nine epochs, but performance was qualitatively very similar across all regularized architectures.
First, we can test our initial hypothesis that the network should perform better with the displayed guidelines to serve as visual navigation cues. Rather than visualizing the pixels that receive the largest response from the network, which we used to understand how the network “saw” the ski race course, we can simply toggle the guidelines and compare the evaluated networks. First, we look at the network with the guidelines toggled on. We observe that the trained network displays some non-trivial behavior. It seems to understand the importance of the guidelines, and it usually reaches the first checkpoint successfully. It rarely reaches the second checkpoint before crashing. A video showing a representative evaluation of the trained network with the guidelines displayed is shown below.
Next, we look at the same network on the same course but with the guidelines toggled off. The network now reaches the first checkpoint less reliably and never reaches the second checkpoint. We can see a representative example of the network evaluation in the video below. Clearly, the network benefits from the guidelines, suggesting that it is trying to respond intelligently to the visual cues. And encouragingly, the network seems to exhibit an attempt at reaching the checkpoint even without the guidelines, suggesting that it is also able to understand the broader objective at some level.
To get a better idea of the overall ability of the network to make decisions in practice, I ran the network again but I served as a sort of “driving instructor” with my own emergency controls. I let the network navigate the course, but I intervened to try to protect it from certain failure. This is a very qualitative method of evaluation, but it is perhaps more informative than terminating the network upon the first failure. At the very least, it demonstrates the navigational choices of the network over the entire course. Additionally, when I interview with direct keyboard input, the neural network is still running and inputting virtual keys. Therefore, I have to “wrestle” with the network for navigation control, and if the network believes too strongly in the wrong direction I am unable to correct it. In the video below, I show the network again attempting the course but show a red frame indicating when I intervene to correct the navigation course. As a disclaimer, unlike the above videos, I did cherrypick this evaluation a bit to choose an instance that required less human input than others.
This video with human intervention paints a very different picture than we get from looking at the validation set metrics or the unassisted neural network evaluation. The network outputs a sufficiently intelligent response to the majority of the frames. There are a number of brief problematic areas that repeatedly require intervention, but the network understands how to output a reasonable navigation trajectory for the majority of the course. And surprisingly, the time required to finish the course warranted a bronze medal, despite never using the rocket to increase our velocity.
Conclusion
We were able to gather a sizeable dataset and use data augmentation to create a series of labelled frames that allowed a neural network to navigate the rocket suit course. The neural network was far from perfect, and required several human interventions to reach the finish point. If the benchmark was expert human performance in its completion of the course, the neural network was not successful. However, I think it did remarkably well, considering it had no sense of temporal dynamics or the physics of the game engine. I suspect that even expert humans would struggle to navigate the course if they were only given single frames to choose a navigation label.
I suspect with enough fine-tuning, one could train a neural network to successfully complete the course without any human intervention. To achieve this, I believe it would be necessary to increase the number of frames on identified problematic areas of the course and also better tune the hyperparameters. We performed no tuning of the optimizer, learning rate, momementum, etc. We also barely scratched the surface in terms of the possiblities of both network architectures and regularization. Such fine-tuning of the system lies outside the capabilities of my available computation, as training each network for ten epochs requires more than thirty-six hours. However, I think the most interesting part of this problem was establishing a proof-of-concept that a form of imitation learning could yield reasonably intelligent navigation across a complex course with the proper visual cues.
Accompanying Code
The code for this project is hosted on my Github account. Nothing about the code is specific to Steep, so you can use this to train a neural network on any video game of your choosing. The code is split up into two categories. The code to record the game frames and the key presses to build a training set is available under this repository, and the code to train a neural network on the generated training set and evaluate the trained network is found in this repository.