Machine Learning
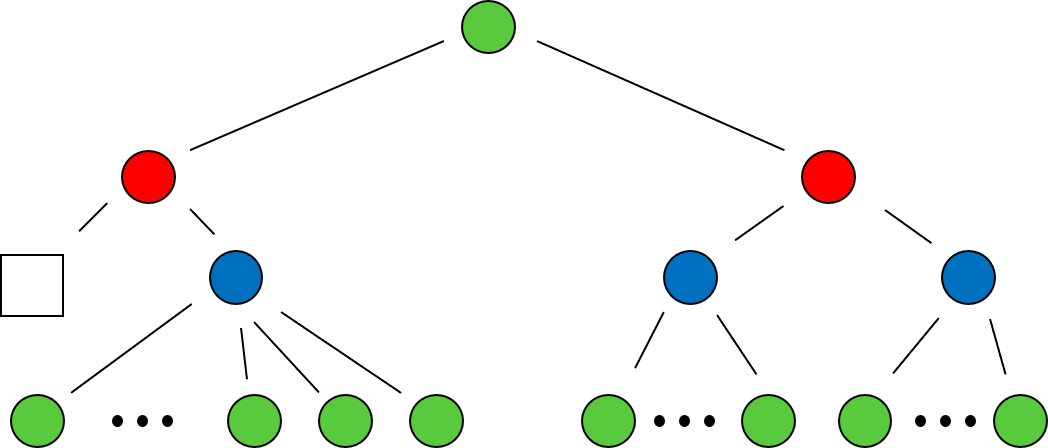
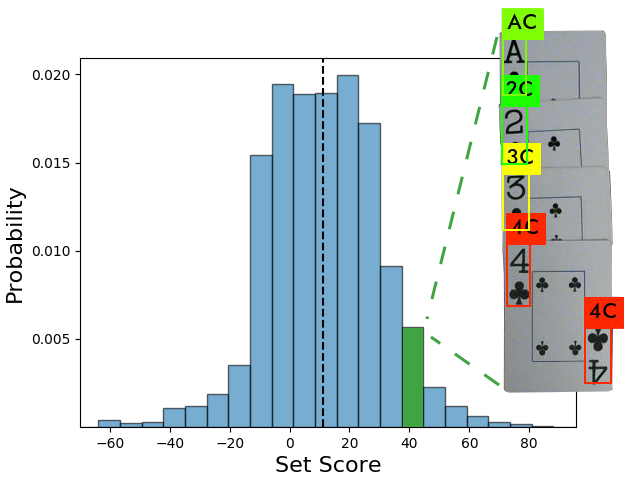
My passion for generating models and understanding data has naturally lead to my interest in the field of machine learning. While pursuing my physics PhD, I also took several graduate level courses to learn the fundamentals of data science and machine learning. To explore beyond the mathematical background and toy problems that I learned in my courses, I worked on several projects during my free time to solidify my knowledge of the practice of data science. These hobby projects were inspired by my other hobbies, primarily playing board games with friends. Below you can browse several of these projects and the accompanying code repositories.