Steep: Imitation Learning to Complete Ski Races
Steep is an open-world winter sports game that allows players to participate in downhill skiing races, among other activities. Because of the open-world design, I was interested in trying to create a neural network that could complete the different races. I trained a neural network using imitation learning, creating training data from my own gameplay and augmenting it to create a sizable training set. How close to human performance can we achieve from a neural network trained using imitation learning?
Introduction
In May 2019, I saw online that Steep was free to download for a limited time. It’s open-world design made me interested in the possibilities of combining machine learning with winter sports. After downloading the game and playing around, I decided on my goal: try to train a neural network that would be able to complete the different ski races. Each race consisted of a number of checkpoints that had to be passed before the finish line could be reached. Imitation learning seemed like a reasonable place to start, since it would be relatively simple to implement. The idea is that I would be the human “expert,” making an action choice for each observation. For this case, the action choice is the combination of keys pressed to navigate the avatar, and the observation is the frame of the videogame. The goal is to train a neural network that can mimic the actions that I would choose for a given frame, allowing it guide the avatar to the finish line in a respectable time.
Steep Controls
Before I begin to describe the approach that I took, I want to briefly introduce the game in a little more detail. The mechanics of the game are quite simple, since the player is only responsible for entering navigation commands through the keyboard. A full list of the possible commands is shown below (Needs to be full res).
 Full list of possible key commands to navigate the ski race course.
Full list of possible key commands to navigate the ski race course.
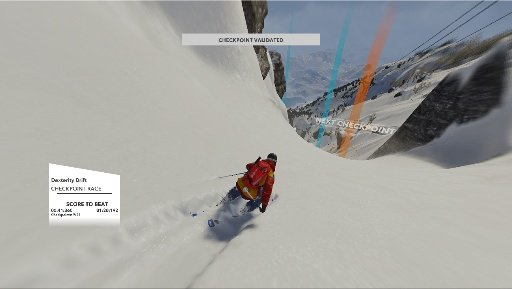
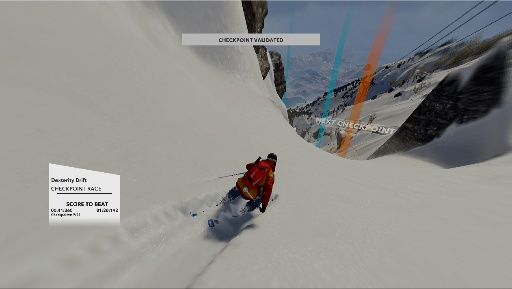
Using these commands, the player controls an avatar on the screen. During a race, the avatar needs to pass through several checkpoints before reaching the finish line. The next checkpoint is shown as an orange pillar of light, and all subsequent checkpoints as well as the finish line are shown as blue pillars of light. A typical frame might look something like the image below.
 Example of a typical scene from a ski race course.
Example of a typical scene from a ski race course.
Our hope in this project is that there is enough information in this frame for a neural network to determine the correct combination of keypresses to guide the avatar to the next target. By collecting a very large number of frames, we hope that a neural network can identify the relevant features in each frame to make a rational choice of the available actions.
Network Architecture
Before I begin to describe my approach to the collecting of data and training of a neural network, it is important to think carefully about our specific choice of algorithm. We use choose to try imitation learning to learn from data recorded from my personal gameplay. However, there are other approaches that one could use for this problem. The most obvious idea would be to use reinforcement learning, since we have a very natural reward function—the time required to finish a given course. However, this natural choice of reward function is extremely sparse. For very simple toy problems, such as the Mountain Car Problem, using time as the reward function leads to good results. This problem is described on the OpenAI Gym website as
A car is on a one-dimensional track, positioned between two “mountains”. The goal is to drive up the mountain on the right; however, the car’s engine is not strong enough to scale the mountain in a single pass. Therefore, the only way to succeed is to drive back and forth to build up momentum.
One may be tempted to use the same type of algorithm for our race problem, since the problems appear similar superficially. However, there are several key differences between the two problems:
- The Steep race is only finished after
$\mathcal{O}(10^3)$decisions are made, all of which in combination lead to the final time. This sparsity in the reward function leads to very poor exploration of the environment, and the neural network will struggle to learn from the exploration that is performed without feedback. - Our action space is much larger with the Steep game because many different keys and combinations can be used for naviation. In the mountain car problem, there are only three available actions.
- Our observation is much larger as well. For the mountain car problem, we are provided two scalar observables: position and velocity. In our case, our observation is a large image. We first need to reduce this high-dimensional image into a much smaller number of features using a convolutional neural network. Even this reduced feature set will be much larger than the two present with the mountain car game, however.
For these reasons, using a vanilla reinforcement learning algorithm did not seem like the most natural approach. If our only metric were assigning the correction actions for a given frame and we had no computational constraints, we would likely gravitate towards a hand-crafted reward function with reinforcement learning and adding an architecture that would account for the sequential nature of navigational decision-making. For instance, we could imagine using a recurrent neural network or even an attention model to recall information from previous timesteps. However, I have the additional hardware constraint that the same GPU running the game is also responsible for evaluating my neural network. If the neural network is complicated enough that it requires a full second for its forward propogation, for instance, we are losing any advantage from a more complex network from the corresponding loss in frames. Due to this computational barrier, using a standard neural network unable to account for time seems like the best compromise for this problem.
Collecting Training Data
A major concern with training any neural network is collecting enough quality training data. This is especially relevant for imitation learning, since the network will always be limited by the “expert” that it is attempting to mimic. For Steep specifically, there are two major problems with collecting training data.
- I am not very good at the game.
- I do not enjoy the game enough to record tens of hours of gameplay.
The data collection pipeline that I use needs to be able to overcome these potential problems. Additionally, another major concern with this project is performance. Due to the limitations of my machine, the same GPU that will be running the game will also be responsible for evaluating the neural network to control the avatar. This is an important consideration even during the data collection process, since we want the collected data to be similar to the data that will be provided to the neural network.
Before we can have a data collection pipeline, we first need to be able to collect data from the game. Like most games, it does not provide standard users with an API, so all of the information needs to come from the rendered frames as well as the input provided by the user. To capture the game frames, I use the win32gui module from the pywin package. This package provides low-level access to API that Windows uses to create the GUI. The advantage of using this package over something more accessible, such as OpenCV, is performance. I find that the framerate that I can record using the win32gui package is almost an order of magnitude improvement over using OpenCV. We also need to be able to both record keypresses issued by the user and input virtual keypresses from our neural network. To avoid many of the complications of Windows virtual key codes, I use the win32api module from the same package.
Now I have a way to play the game and record all of the information we would want to train a neural network. To minimize the amount of computation and memory required by the GPU to play the game, I set the resolution the lowest available option, 1024 x 768, and use the lowest settings for all of the graphics options. To efficiently train a neural network, we want to use images as small as possible. Many image classifiers work with much smaller images than the lowest possible game resolution. We want our images to be as small as possible to quickly train and evaluate our neural network but large enough to still encode enough information to allow an intelligent decision to be made from the provided pixels. Through experimentation, I found that I was still able to navigate the different race courses using a window size of 320 x 180. This resizing and other preprocessing was performed using OpenCV. After a little optimization, I was able to grab the game screen, perform basic preprocessing, and save the screen and keypress data at 30 frames per second, which is plenty fast to allow fine-grained control over the navigation of the avatar.
The only remaining hurdle to overcome before I could start recording training data was my mediocre skill at the game. While I was able to reach the finish line in most of the courses in the time required to get a gold medal, I was certainly not able to do this consistently. I also had frequent crashes into trees and other objects. If the neural network is going to learn from my play, its absolute ceiling is my performance, and in practice it will be much lower. I want to hide my mistakes so that the training data only contains data worth learning from. My solution was inspired by the controls of the game. Pressing the “tab” key resets the avatar at the start of the course. I added the ability to listen for this keypress event in my keylogger. Now, whenever I reset my avatar after crashing, the data recorded over the seconds preceding disaster were removed from the buffer.
We now have all of the tools in place for me to race as long as my patience allowed. And importantly, training data would be collected in the background with no effort required on my part, and it would conveniently remove information that I would not a neural network to learn from. I recorded around three hours of gameplay across fifteen different courses, which I repeated as many times.
Data Processing Pipeline
I will now describe the data processing procedure for the specific data recorded as described above, but the same procedure will be used for further experiments that I will later describe. After recording my game data, I had 360,000 pairs of frames and associated keypresses. This seemed like a reasonable amount of data that we could hope to use to train a neural network. However, there are other concerns than just quantity of data. The biggest concern is level of imbalance in the different keypresses in our raw training data. Because I am trying to achieve the fastest times possible for each course, the “W” key, which corresponds to moving forward, is present in a disproportionate number of the keypress events. If we do not correct for this, the neural network could simply return an output corresponding to “W” for every frame and perform reasonably well with any loss metric.
The easiest and least clever solution to data imbalance is to simply delete the extra frames for each overabundant class. The obvious downside is that we are throwing away useful data. This method would leave us with very little training data, so that we would be required to spend many more hours capturing gamplay, even though most of it would end up being deleted.
Instead, we use data augmentation to increase the size of the classes that do not have enough samples. We use the existing frames to generate artificial frames that should require the same keypresses as the original frames. This solution to data imbalance allows us to expand our training set to any desired size. Furthermore, it has the additional benefit that, if performed correctly, can make our recorded dataset more robust to insignificant features. As one example, the videogame has a full day-night cycle. However, I did not record enough data to cover all of the possible different lighting conditions. Data augmentation could allow us to add different lighting artifacts to make us more robust to these lighting conditions so that our perfomance is not impacted by the time of day.
Before we explore different methods to augment the recorded frames, we first need to determine which keypresses are worth including in our training set. I counted all of the key presses recorded across the raw training data, shown in the figure below. I only kept keypresses that comprised 1% of the recorded data. The reason for this was twofold. First, very rare key press combinations should not be necessary to navigate the course. Our neural network should be able to perform better if we do not include extraneous classes. And secondly, the data augmentation is not perfect. Although we can artifically expand these rare keypress combinations up to any desired size, the data will contain bias if the number of generating frames is relatively small.
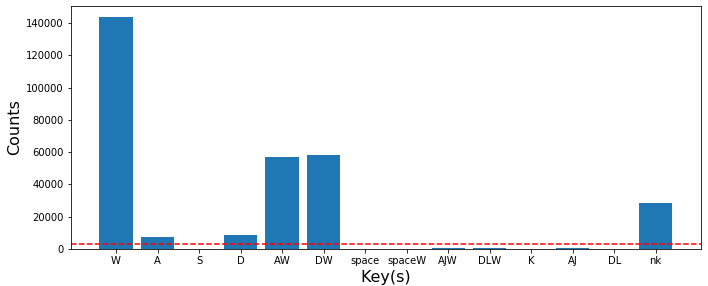 Key presses recorded during gathering training data, with the significant threshold shown in the red line.
Key presses recorded during gathering training data, with the significant threshold shown in the red line.
Data Augmentation
With the relevant keypresses identified, we can explore different methods to augment our recorded frames using OpenCV, numpy, and scipy. We note that the frames requiring turns are underrepresented. The turns especially are important to identify, since the turns result in major corrections to the navigation trajectory. Our first method of augmenting the data is flipping the frames requiring turns. The assumption is that if the scene were mirrored, we would require the keypresses to be mirrored to achieve the same effect. This method is imperfect, since we can immediately see that the mirrored frames could never occur from playing the game. Ideally, our augmented frames should look like a scenario that we could encounter in the game. However, in this case I think that this shortcoming is acceptable, since the neural network should not be paying attention to the location of the HUD to inform its action choice.
 Original frame recorded from gameplay.
Original frame recorded from gameplay.
 Mirrored frame to increase turn data.
Mirrored frame to increase turn data.
Another way to augment our data deals with changing the lighting. For a given frame, we want to perform the same action even under different lighting conditions. We can first create an artificial frame by offseting the pixel values by a single, randomly chosen value. This is shown in the top frame below. We can also had noise at the pixel level, as shown in the bottom frame below.
 Adding a constant random intensity value to all of the pixels in the original frame.
Adding a constant random intensity value to all of the pixels in the original frame.
![]() Adding random pixel-level intensity values to the original frame.
Adding random pixel-level intensity values to the original frame.
Another way to introduce lighting artifacts is to artificially superimpose a sunspot on the image. We can generate a 2D gaussians of random intensity and position and overlay this onto our recorded frame, as illustrated below. The direction of navigation should not be impacted by the artifical sunspot, so this is another tool at our disposal to generate more data.
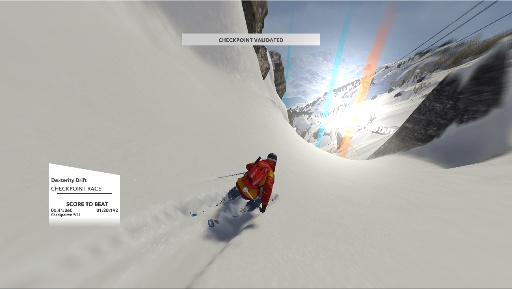 Adding random sunspot to the original frame.
Adding random sunspot to the original frame.
Finally, the last tool at our disposal is to randomly distort the image using a random elastic transformation. We expect that a small distortion should not change the correct keypress to navigate to the next target, although we need to be careful to not apply too much distortion. An example of applying this elastic transformation is shown below.
 Distorting the image by applying a random elastic transformation to the original frame.
Distorting the image by applying a random elastic transformation to the original frame.
We now have several different techniques at our disposal for generating artificial frames from a given recorded frame. Importantly, with the exception of the mirror transformation, all of these can be applied multiple times to the same frame to produce different artifical frames. Using these techniques, we expand the data for underrepresented class labels so that our training set has an equal number of all of the relevant keypresses.
Evaluating Network Architectures
We have a lot of freedom in choosing the architecture for our neural network that will learn from this large labeled dataset. We will liekly want to use some convolutional neural network layers to extract features from the frames, and we know that our final layer should use a softmax to choose the best action for the given frame. Outside of these layers, however, we have considerable freedom in designing an architecture to perform well for our problem. Designing state of the art classifiers is currently more of an art than a science, so there is no procedure for developing a classifier for our specific data. Rather than reinvent the wheel, we can take advantage of existing architectures that have demonstrated success in classification tasks. In addition to improved ease of use, these existing architectures will give us a much higher chance of success. The only limitation from using the state of the art image classifiers is that we need enough video memory to store both the network architecture and Steep, which requires 2 GB of memory on the lowest graphics settings.
I first started using InceptionResNetv2, a convolutional neural network architecture that achieved state of the art accuracy in the ILSVRC image classification benchmark. Because our image data is sufficiently different from the images in the benchmark, I did not want to use any transfer learning but instead opted to train the network from scratch.
With a network architecture in place, the next step is to split up our data into a training set and a validation set. We also want to feed the network batches of random frames. If we instead grab the frames in order, there will exist large temporal correlations among all of the data within each batch, which will inhibit the ability of the network to converge properly. We can easily perform this using a custom dataloader in PyTorch.
Although the network was able to converge to produce a small training and validation loss, the performance of the network in practice was poor. The real benchmark for this problem is the network’s ability to intelligently navigate the various race courses. I believe that part of the problem is from the complexity of the InceptionResNetv2 architecture. While the network was controlling the avatar, it was only able to play the game at around 4 fps due to the amount of need required to evaluate the neural network. Anyone who has ever tried to play a demanding video game on an underequipped computer knows the difficulty of trying to react to events in real-time with such a poor framerate.
For this reason, I wanted to try a less complicated network architecture. Although a smaller network will come with less accuracy on many of the standard image classification benchmarks, there is a trade-off in increased throughput. We may prefer a network architecture with slightly worse accuracy on each individual frame if it is able to process many more frames per second. A natural choice of alternative architecture was ResNet50, another convolutional neural network that performed very well on the ILSVRC benchmark. ResNet50 was the state-of-the-art architecture before InceptionResNetv2 and motivated part of the design of InceptionResNetv2, as one may expect from the name.
I trained ResNet50 from scratch, again opting to avoid transfer learning for the potential of better classification for our specific images, and this network was also able to converge to produce relatively small loss values for both the training and validation images. The big advantage of using ResNet50 came when allowing the network to play the game in real-time. This architecture was able to play the game at 15 fps, which is very acceptable for real-time navigation control.
Initial Network Attempt
After training ResNet50 with the augmented dataset, we observed that the training accuracy was very high (over 90%) but the validation accuracy was only slightly better than randomly guessing. Not surprisingly, when evaluating the trained network, the avatar was unable to competently navigate any of the race courses. A representative evaluation of the network playing one of the most simple race courses is shown below. The network does a few things correctly but is largely incompetent. In looking at many evaluations of the network, I observe that the network often gets to the first of the sixteen checkpoints, but almost deterministically swerves to the left on the wrong side of the hill, as shown above. I believe what is happening is that the network has a biased response to large hills that it learned from another course, which required the avatar to circumvent the large hill by going to the left of it. Although the network received training data that was balanced in terms of the classes, it was still biased in terms of its features. In this specific example, for instance, there were not enough frames in the training set showing a large hill that required a right turn.
The inability of our neural network to consistently navigate the different race courses is not surprising. First of all, we are losing a lot of information by treating this as an individual image classification problem. It would be difficult for a human to choose a navigational course based on a single image of the game. Even if we provide a human with a small sequence of images, determining the proper navigation is difficult. The issue is that there are few guiding features on the mountain. The pillars of light showing the location of the next checkpoint and the finish line are often not visible, and they are often very far away even when visible. In this sense, controlling an avatar through a ski race is more difficult than controlling an autonomous car, because we do not have anything analogous to road lines or signs to inform our navigation on a finer length scale.
Another obvious shortcoming with this approach is the simplicity of our architecture. As I mentioned in the discussion of alternative approaches, we would like to do something more advanced than image classification. This could involve using RNNs to account for the temporal nature of a navigation problem and/or creating some reward function for use with reinforcement learning. The issue with these alternative approaches is that I am very limited in terms of hardware. When a single GPU is tasked with running the videogame and evaluating a neural network in real-time, the complexity of the network is severely limited.
Revised Network Attempt
To try to salvage all of the work spent on the data preprocessing pipeline, I reduced my more ambitious goal of training a general ski course racing algorithm to instead try to perform well on a single course. The benchmark course illustrated above is the easiest course in several key regards. The course is relatively simple, requiring few complicated navigation sequences, and is relatively short, requiring just over a minute to complete. And most importantly, the course has a very large number of checkpoints, so that the next checkpoint is almost always visible. This is important since it should allow a well-trained network to gain an understanding of a high-level goal in the short term.
To gather training data for this course, I played this single course repeatedly for approximately four and a half hours and recorded my keystrokes. An example of a single completion of the course that I performed is shown below, which illustrates the decisions we hope that the network will be able to make. For this dataset, I restricted my play to only using the three most common key combinations (those corresponding to forward, forward-left, and forward-right) to reduce the number of classes that the network would need to choose between. After all of the data was recorded, I had approximately 450,000 labeled training frames.
If we had no data augmentation, we would have to reduce the dataset until all classes were equally represented. Performing this truncation on our dataset, we are left with 280,000 labeled frames. After training a neural network on this small dataset, I observe extreme overfitting and poor performance in practice. But since we have a set of tools to perform data augmentation in our preprocesing pipeline, we can instead expand our dataset to 600,000 labeled frames and train a network with this much larger dataset. Looking at the loss and training accuracy calculated on the validation set below, we still see significant overfitting.
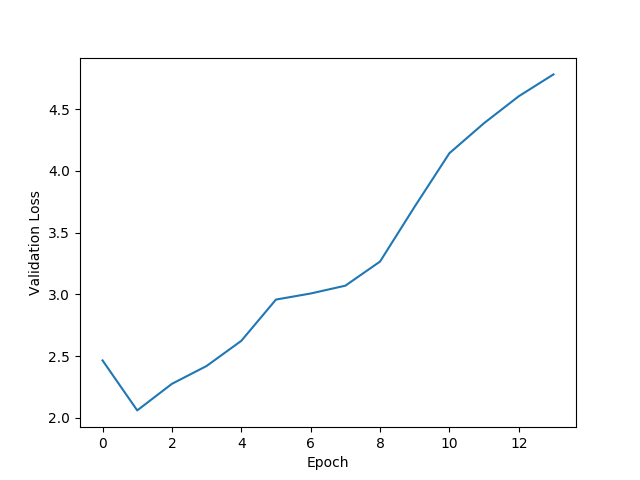 The loss calculated on the validation set does not improve with additional training epochs, suggesting that the network is failing to generalize to new data.
The loss calculated on the validation set does not improve with additional training epochs, suggesting that the network is failing to generalize to new data.
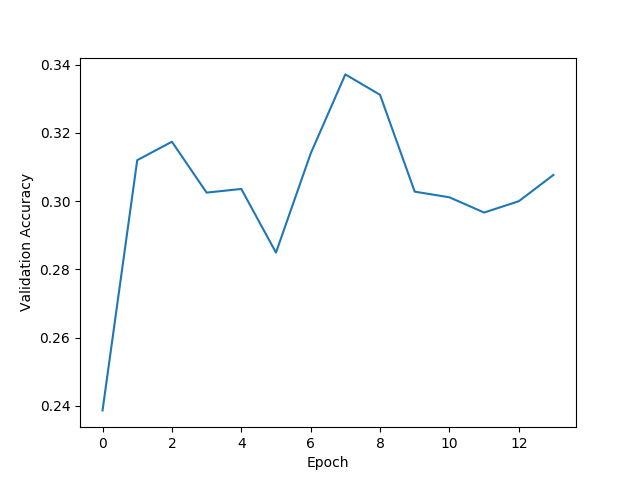 The accuracy on the validation set does not improve past the same accuracy one would obtain by randomly guessing.
The accuracy on the validation set does not improve past the same accuracy one would obtain by randomly guessing.
Such overfitting is not a huge surprise. Because the ResNet50 model has 23 million trainable parameters, it has the ability to somewhat “memorize” the training images instead of learning from them. And remember that the task we have given the network is very hard—not only does it need to determine the proper navigation from a still image, it also has to deal with the fact that the same image could have multiple acceptable keypresses depending on the trajectory chosen, even though the network has no exposure to this information. For these reasons, memorizing the training images is likely an easier task than developing a robust mapping of an input frame into a desired keypress.
However, I do not believe that the simple metrics on our validation set are sufficient for evaluating the performance of our network. Unlike traditional image classification problems, the ground truth label for almost every frame can take a number of values that would stil lead to a successful completion of the course. While there are certain frames with only a single acceptable response, many of the frames can take several responses provided the following responses are reasonable. So the best way to truly understand the ability of the network to complete the course is to watch it. In the video below, we see very surprising results given the validation metrics—the network successfully completes the course, even achieving a gold medal for its time. Although there are obvious imperfections with obstacle avoidance, the output of the network for this run could easily be confused with the output of an imperfect human.
Understanding Overfitting
How do we reconcile the overfitting evidenced in the validation set with the impressive performance in the video above? It turns out that the two are not mutually exclusive in this case. I did not have to evaluate the network on dozens of attempts to record the video above, but the output of the network is not always so competent. After completing the course, I ran the network again and obtained the following video. This shows a network that is much less convincing. It still does several things correct: it understands the high-level course of action needed to complete the course, and it even performs a few impressive maneuvers to salvage its attempt (particularly around the 0:52 mark in the video, which is difficult due to the lack of momentum and the slope of the mountain). However, there are certain suboptimal patterns that it cannot seem to escape, namely the pattern of going back and forth at the cost of its momentum instead of going straight. In this run, the network does successfully reach the finish line, although I spared the viewer from watching the remainder of the attempt.
The network has clearly learned something, displaying intelligent behavior in both runs. However, its evaluation is unstable. It can correct from small deviations from the trajectories over which it has training data, but it fails to fully abstract a robust navigational procedure that can generalize to larger perturbations. For this reason, a single evaluation of the network relies on a bit of luck to appear competent. When the network gets started on a trajectory very similar to those that it trained on, it can successfully complete the course and achieve a gold medal. One of these runs finished in 1:20, only 10 seconds slower than my single best attempt. However, for every successful completion there are several that look like the previous video or even worse. It is not uncommon that the network is unable to complete the course at all. In these cases, the overfitting is painfully obvious as the network fails to respond to frames that differ slightly from those in the training set.
One solution to the very specific issue we observe in the above video is to modify the final softmax layer to determine the action choice. Recall that we balanced our training set so that all of the classes were evenly represented, but we know from looking at our recorded data that not all actions should be equally likely. One can imagine forming a prior using the initial label distribution to bias the network output towards the actions that we know should be more prevalent. I had a little success attempting this hack, but is very specific to this specific issue and far from a true solution to our overfitting issue.
Visualizing Trained Network
One way to better understand the overfitting present is to try to understand how the neural network responds to a given input frame. We can visualize its response to a given frame by generating a saliency map. The idea is that we can perform backpropagation for our input image and quantify the degree that each pixel was used to determine the final class prediction. This quantification relies on calculating the derivative of the class score with respect to the input image at each specific location. Intuitively, the resulting saliency map can be loosely thought of as a visualization of where the network pays attention in the image, since it illustrates the pixels determined to be most instrumental in forming its decision.
We will use the below image to generate a saliency map to probe our network. Before we display the saliency map, though, let’s think about what we would expect to observe if our network had been trained well. Our network is choosing between moving forward-straight, forward-left, and forward-right. If we had to choose among these options for this frame, which features would we want to pay attention to? We may want to consider the location of the next checkpoint, as this dictates the long-term strategy. For our immediate decision, we would want to take note of the tree to our left to avoid running into it. We would also want to look directly ahead of us and to the right of us to check for obstacles in these directions. And perhaps we would even look behind the avatar at the ski marks to get an idea of the previous direction of travel. Now combining all of these observed features into a navigation ruleset is non-trivial, but we would expect a well-trained network to focus on many of these features into its determination.
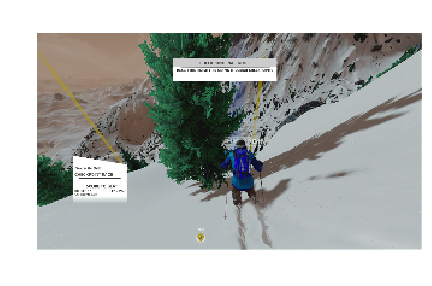
This example image comes from the training set, so we know the ground truth label. In this case, the navigation choice that the network aims to imitate is to move forward-right, which seems very reasonable given the location of the tree. Looking at the output of the final softmax layer of our network, we see that the network correctly chooses the correction navigation, choosing the forward-right choice with 97% probability. We can now generate a saliency map from this frame to understand the groups of pixels that the network uses to arrive at its decision. I used the python package FlashTorch to calculate the saliency map and visualize it after some minor modifications. The different steps of the saliency map generation are shown in the below figure.
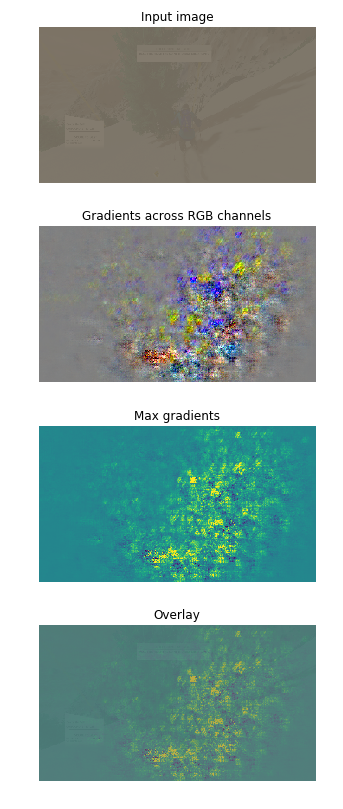 Generating a saliency map to help us to understand how our neural network analyzes frames.
Generating a saliency map to help us to understand how our neural network analyzes frames.
The top panel simply shows the original image, after it has been preprocessed for use in our neural network. The frame seems much more gray than the frames I have showed you because we normalize and standardize all images to help with convergence. In the second panel, we see the spatial gradients with respect to class label across all three color channels. The third panel shows the maximum gradient for each pixel, and the fourth panel shows these gradients overlayed on the original image. However, the original image is difficult to see after the normalization process, so I reproduce the overlay in the figure below using the untransformed image and a different colormap.

Here we can clearly see that network seems to pay most attention to the pixels in the vicinity of the avatar, as we would expect. The network correctly identifies a large region of open area to the right of the image, and most of the neural activity occurs here. However, many of the pixels that strongly impacted the decision of the network do not correspond to any of the anticipated features. In fact, these pixels do not correspond to any discernable features but instead noise. We see, for instance, that many of the pixels representing a distant mountain are being used to form the decision for this frame. This example nicely illustrates the overfitting present. The network is taking inventory of many of the relevant features to determine its action choice, but it is also relying on the specific memorized values of uninformative pixels to reach its decision. This helps connect the dual nature of the network we observe in the above videos to the overfitting we observed looking at our validation curves.
Improving Network Performance
Stable Network Evaluations
My only real concern with the neural network is its consistency. Its best completion time of the course would rival that of many human players, but it cannot consistently achieve this. To achieve perfectly reproducible human-level performance of the course, I suspect that some combination of additional data augmentation and network regularization would be necessary.
In terms of data augmentation, we likely would need to gather additional training data on the portions of the course for which the network is most at risk of serious deviations. We may also require gathering data from subpoptimal initial conditions to try to teach the network how to better recover from these deviations. However, gathering this data is very time-consuming, especially for the second issue, since only a small fraction of the user’s play time can be converted into training data of the desired nature.
We also likely need to experiment with some combination of dropout layers and weight regularization to reduce the ability of the network to simply memorize its training data. These measures would help encourage the network to isntead form a robust mapping from frames to navigational decisions and help minimize the impact of deviations from the training data. However, a thorough optimization of these architecture modifications and their associated hyperparameters would require a very large amount of computational time, which simply is not feasible for my personal computer.
Superhuman Performance
Finally, if our goal were to achieve truly optimal course times, we would want to use a different algorithm altogether. One idea that I have been looking into is to attempt to create a very light reinforcement learning architecture. We can use transfer learning to take advantage of the underlying layers of our trained ResNet50 model. Our reward function likely should be a function of the time spent on a given course as well as the number of checkpoints passed. This information is available to the player in the HUD, but the neural network has no knowledge of this information, even though it is present in the recorded frames. I was able to clip out the relevant portion of the screen, as shown below, and then run optical character recognition on this portion of the image using PyTesseract, a Python-wrapper for Google’s Tesseract OCR engine. I am still experimenting with how to best incorporate this information into a reward function that allows an agent to successfully navigate the different course environments, but check back in the future for more result.
Conclusion
I was able to develop a data preprocessing pipeline to create a balanced training set for use with a neural network from my own gameplay. Using imitation learning, I was able to train a network that could successfully complete the desired ski course with a gold medal time. This was achieved despite the network havingf no knowledge of temporal information, previous frames or actions, or any of the physics of the game engine. However, significant overfitting prevented this from being a reproducible outcome. Future work will be directed towards reducing this overfitting to achieve consistent human-level performance on our desired course. Achieving human-level performance across a number of different courses seems to require more training data and computation than is feasible for my personal computer.
It is also possible that the inability of our network to learn to consistently navigate the course is more fundamental than a slight architecture or hyperparameter choice. In some sense, formulating a robust mapping for the ski problem we have looked at is more difficult than the issue faced with autonomous cars, at least along a certain axis. Although there are many more intracacies required for a self-driving car, the autonomous vehicle problem has the benefit of many visual cues to help determine navigation. For example, the road lines, the median, sidewalks, stop signs, etc. can all be used to help inform the steering at a high-level. On the side of a mountain with none of these guiding features, determining a robust navigation ruleset is more difficult. Understanding the trade-off between additional visual cues and more challenging environments would be very interesting.
Accompanying Code
The code for this project is hosted on my Github account. Nothing about the code is specific to Steep, so you can use this to train a neural network on any video game of your choosing. The code is split up into two categories. The code to record the game frames and the key presses to build a training set is available under this repository, and the code to train a neural network on the generated training set and evaluate the trained network is found in this repository.